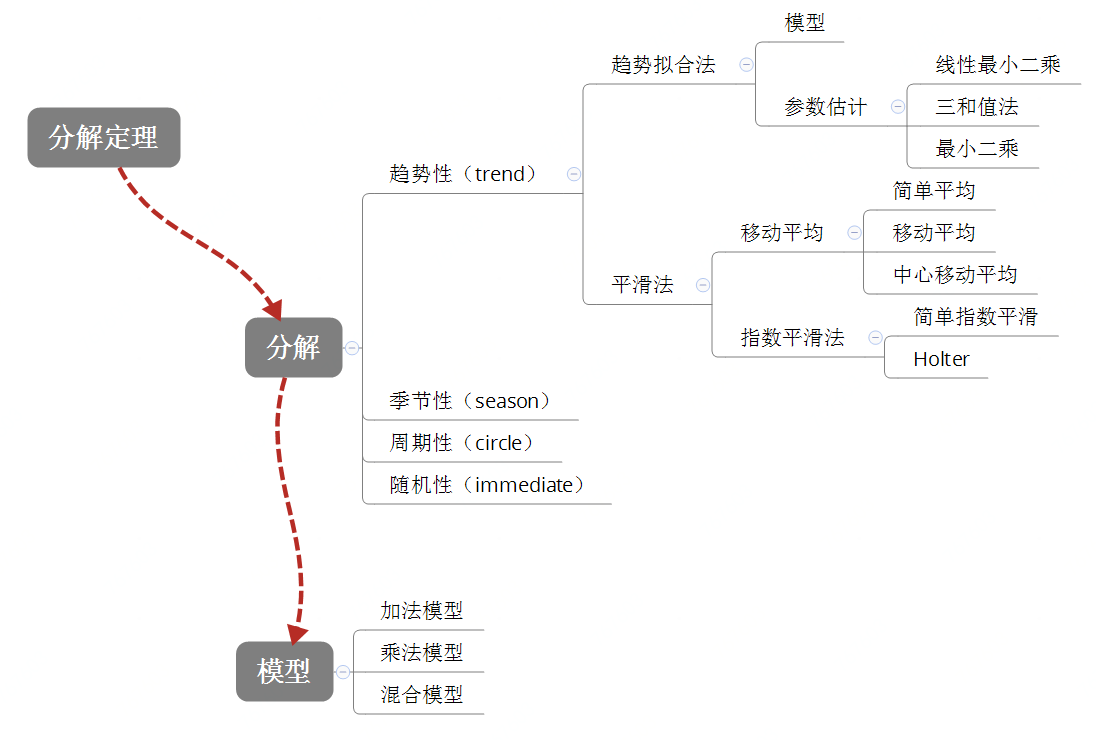
先看此知识体系:
(1938)
任何一个离散平稳过程xt都可以分解为两个不相关的平稳序列之和,其中一个为确定性的,另一个为随机性的。
xt=Vt+ξt
其中,
- Vt是确定性序列
- ξt=j=0∑∞ϕjεt−j是随机序列
- ϕ0=1,∑j=0∞ϕj2<∞,也就是收敛
- εt∼N(0,σε2),也就是白噪声序列
- E(Vt,εs)=0,∀t=s
下面定义什么事 确定性序列 和 随机性序列
yt=a0+a1yt−q+a2yt−q−1+…+vt
vt是残差,定义τq2=Var(vt)
- 如果q→∞limτq2=0,那么yt叫做确定性序列
- 如果q→∞limτq2=Var(yt),那么yt叫做随机性性序列
例如:
ARMA模型
xt=μ+Φ(B)Θ(B)εt
首先是离散平稳过程,其次两部分分别是确定性序列、随机性序列。
(1961)
任何一个时间序列( 不要求平稳)都可以分解成两部分的叠加:
- 一部分是由多项式决定的确定性趋势成分
- 另一部分是平稳的零均值误差成分,
x=ut+εt
- ut=j=0∑dβjtj 确定性影响
- εt=Ψ(B)at 随机性影响
进行分解时,有以下一些方法。
- 结构性分解:需要其它经济变量,用变量之间的关系分离出趋势成分和循环成分,如Okun分解,Philllips曲线关系等
- 状态性分解:通过时间序列的性质,分解成趋势成分和循环成分
- 状态域分解:卡尔曼滤波,差分分解
- 频域分解:H-P滤波,BP滤波
这里只介绍最直观的分解方法。
一个时间序列,可以由以下因素组成:趋势性(Trend),周期性(Circle),季节性(Season),随机性(Immediate)
每个性质的拟合方法是:
具体模型有:
- 加法模型
Yt=Tt+St+It
- 乘法模型
Yt=TtStIt
- 混合模型
- Yt=StTt+Tt
- Yt=St(Tt+It)
- 其它个性化定制的模型
如果季节的波动性与趋势没有关系,那么考虑加法模型。如果季节的波动性随着趋势性变化,那么考虑乘法模型。
下面分别介绍每一个性质的处理方法。
罗列一下常见的模型类型
- 直线趋势模型
Y^=a+bt
- 二次曲线模型
Y^=b0+b1t+b2t2
- 三次曲线模型
Y^=b0+b1t+b2t2+b3t3
- 幂函数曲线模型
Y^=atb
- 对数曲线模型
Y^=a+blnb
- 双曲线模型
Y^=a+b×t1
- 指数曲线模型
Y^=aebt
- 修正指数趋势模型。特点是有增长上限
Y^=L+aebt,a<0,b<0
- 贡伯兹曲线。
Y^=Le−ae−bt,a>0,b>0
特点:
- t→−∞∋Y→0
- t→∞∋Y→L
- 曲线有拐点,先凹后凸
- 皮尔曲线模型
皮尔曲线又叫logistic曲线,较好的描述了生物生长的过程
Y^=1+ae−btL
《统计预测:方法与模型》给出了两种估计参数的方法:线性最小二乘法,三和值法。scipy给出了一种估计参数的方法:最小二乘估计。
把模型变换成为线性模型,然后用OLS进行估计。
例如,贡伯兹模型,可以变换成lnln(L/Y)=lna−bt
优点:可以使用线性回归的所有检验方法(t检验,F检验…)
缺点:
- 有些模型对应多个线性模型。
- 往往残差不是最小。(而是变换后的线性模型残差最小)
把每个间距期分为三段,求每一段的数值和∑1Yt,∑2Yt,∑3Yt,
然后用这三段值解出参数
用最优化方法求:
argmin∑(yi−y^)2
方法见于另一篇博客最小二乘估计
基本思想是:时间序列是某种基本变动和随机误差的叠加。平滑的目的在于消除随机误差。
分类:
用以前所有数的平均值,预测下一个数
Y^t+1=i=1∑TYi/T
在简单平均法中,当T比较大时,早期的数据作用已经不大。
因此用固定的平均期数。
Y^t+1=i=t−T+1∑tYi/T
等价于:
Y^t+1=Y^t+T1(Yt−Yt−N)
Y^t+1=i=1∑Tαii=1∑TαiYi
- 有周期性:以周期为期
- 对平滑性的要求:要求平滑,那么期多
- 对近期变化的敏感程度:要求敏感,那么期少
内容见于【描述时序】指数平滑法.
季节周期数的识别:看自相关图,如果有季节性,那么自相关图也会显现出一定的周期性,看哪个nlag对应的自相关系数比较大,从而识别出季节数。
(如果趋势性明显,就不能用这种方法了。)
Y^t=Yˉfi
其中:
- i=1,2,…,12或i=1,2,3,4,表示每个期限中的第i个
- Y^是所有期的平均
(如果有理由相信每个周期情况一样,用所有期的平均。如果有理由相信最近n个周期情况一样,用最近n个周期。如果有理由相信最近一周期与以往不同,用上一期回溯一个周期作为平均。)
- fi是同期所有数的平均/总平均.
例如,所有的1月份的平均/总平均,就是f1
Y^=(a+bt)fi
其中,
- (a+bt)是趋势部分
对参数估计时,可以用经验法。
也可以用OLS法,
- fi=mYi+Yi+T+…+Fi+(m−1)T
- m是季节个数。例如,年数。
- T是每个季节的长度。
例如原始数据为季度数据时,T=4。原始数据为月度数据时,T=12
fi由公式给出,还需要对趋势部分(a+bt)估计:
可以用经验法。
也可以用OLS法,估计V=a+bt
Y^=(a+bt)+fi
fi的定义同季节交乘趋向模型,fi=mYi+Yi+T+…+Fi+(m−1)T
与季节交乘趋向模型的区别似乎是乘法模型和加法模型的区别?这个存疑
