🔥 计算机组成原理
🗓 2024年05月18日 📁 文章归类: 0x10_计算机基础
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2024/05/18/computer_organization.html
冯诺依曼结构
冯诺依曼结构的要点
- 计算机五大组成部分
- 运算器 CA,central arithmetical
- 控制器 CC,central control
- 存储器 M,memory
- 输入设备,I,input
- 输出设备,O,output
- 数据和程序 均以 二进制的形式 不加区别地存放在存储器中
- 计算机在工作时能够 自动 地从存储器中取出指令并执行
用餐馆做菜来类比
- 主存:货架。货架上的格子上面放着食材和任务单
- CPU:厨师。取出货架上的任务单、食材。厨师的动作非常快
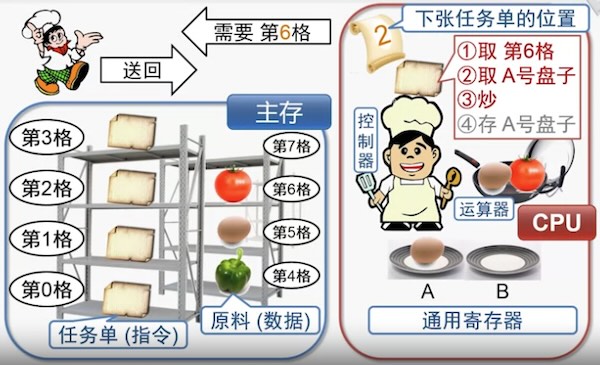
执行一条命令的过程如下
- 取址 fetch
- 厨师查看下一个任务单对应的货架标号
- 根据标号从货架上取出任务单
- 更新下一张任务单对应的货架标号
- 译码 decode
- 查看任务单,发现任务是:取仓库 6 和 A 盘子的原料,炒菜,然后放入盘子A(寄存器)
- 执行 execute
- 取第 6 格的物品
- 取盘子 A 的物品
- 炒
- 放入 A 盘子
- 回写 write-back
- 执行下一条命令(回到1)
参考视频:https://www.coursera.org/learn/jisuanji-zucheng/lecture/EwddN/103-feng-nuo-yi-man-jie-gou-de-xiao-gu-shi
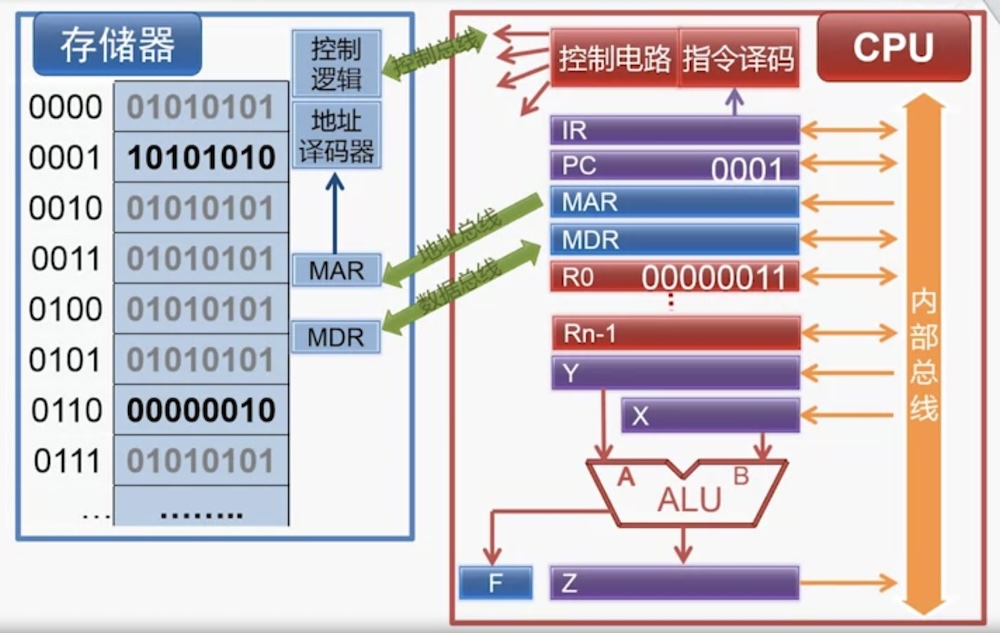
计算机结构的简化模型
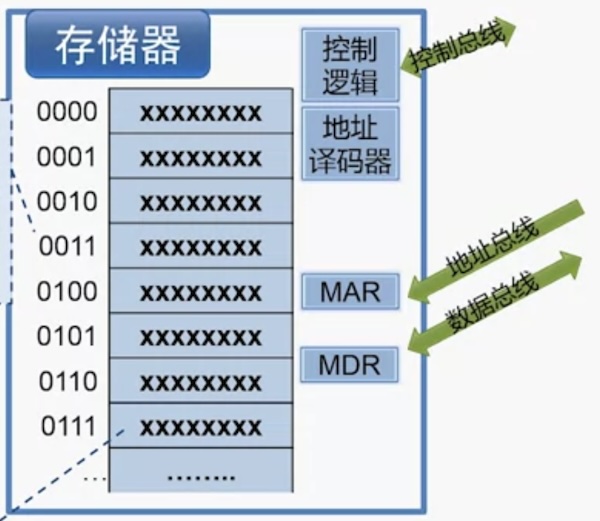
上图为存储器
存储器要点:
- 控制总线用来接收来自CPU的读写新号,或者向CPU反馈读写完成的信号
- 每个地址对应一个存储单元,对应一个字节(8位二进制)
- 地址总线决定了能管理多少个存储单元。
- 32位系统的寄存器宽为 32 位,可以寻址
2^32 = 4GB内存空间。64位系统则是2^64 = 16EB内存空间,不过 64 位通常用地址总线为位为 36、40、48,因为没有必要支持到 16 EB 这么大
- 32位系统的寄存器宽为 32 位,可以寻址
- MAR,Memory Address Register,用于存放 CPU 正在读或者写的存储单元地址
- MDR,Memory Data Register,用于存放正在读出或者即将写入存储单元的数据
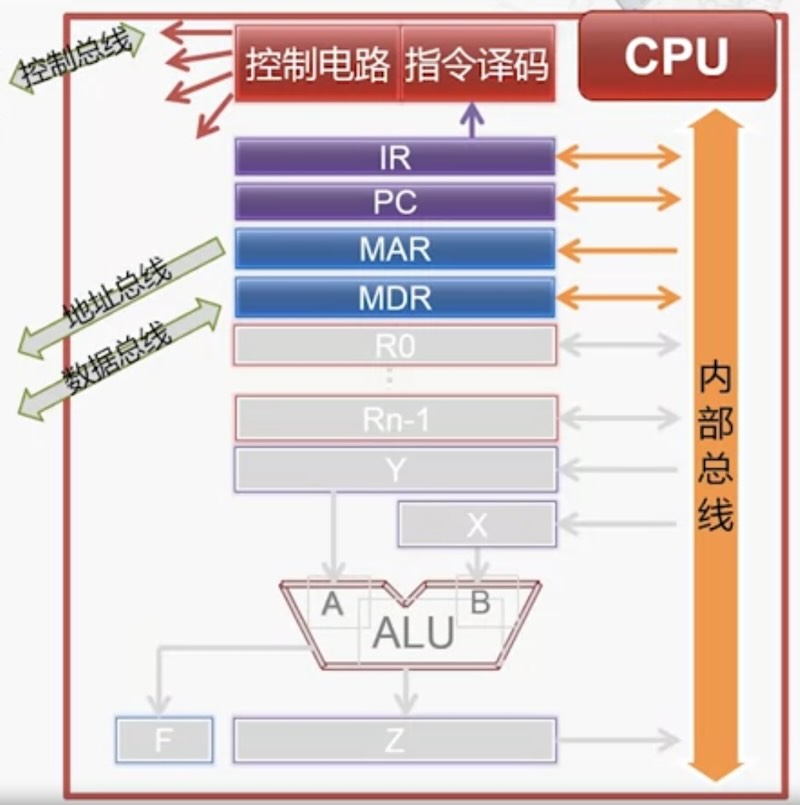
上图为控制器(CPU)
控制器要点:
- 指令寄存器,IR,Instruction Register
- 存放 “正在执行 或者 即将执行的指令”
- 程序计数器,PC,Program Counter
- 存放“下一条指令的存储单元地址”,
- 它有自动增量计数的功能
- 存储器地址寄存器,MAR,Memory Address Register
- 存储器数据寄存器,MDR,Memory Data Register
- MAR 和 MDR 在上面提过了
- 指令译码部分
- 对 IR 中的指令进行译码
- 控制电路
- 产生控制信号,在时序脉冲的同步下控制各个部件的动作
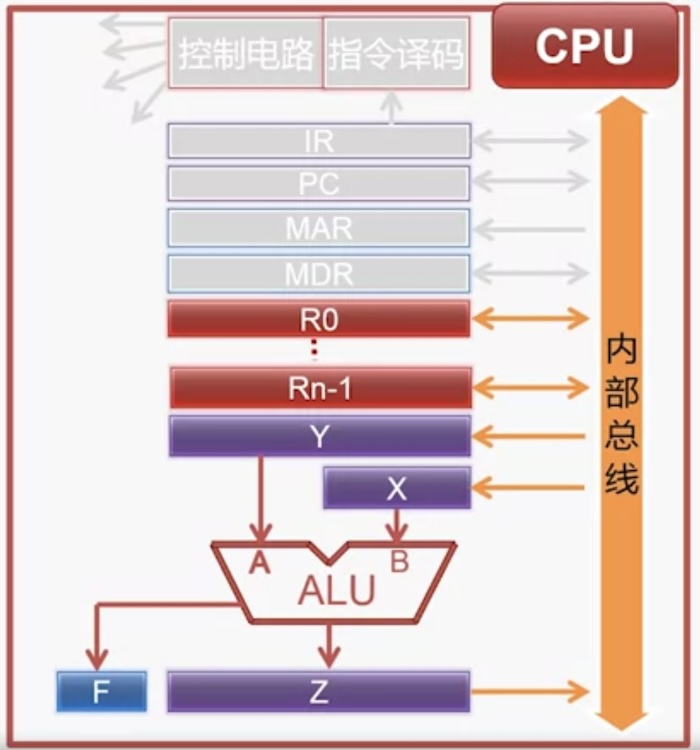
上图为运算器
运算器要点
- 运算器用于算术运算和逻辑运算
- 常见的算术运算:加减乘除
- 常见的逻辑运算:与、或、非
- 核心部件是 ALU,用于完成算术运算和逻辑运算
- X、Y、Z 是寄存器
- F(也是寄存器)用于存放运算结果状态,(零、正负、进位、溢出)
- R0, R1,…, Rn-1 是通用寄存器,其存放的数据可以来自存储器、也可以来自其它通用寄存器或者 ALU 的输出
- 内部总线:用于 CPU 内部各个部件之间传递数据
- 例如,CPU 可以命令 R0 中的数据传给 X,这就是通过内部总线来传递的
- 其电路实现在下面介绍
关于存储器、控制器、运算器的介绍:https://www.coursera.org/learn/jisuanji-zucheng/lecture/1wVRC/104-ji-suan-ji-jie-gou-de-jian-hua-mo-xing
计算机执行指令过程的举例:https://www.coursera.org/learn/jisuanji-zucheng/lecture/8Xyeu/105-ji-suan-ji-zhi-xing-zhi-ling-de-guo-cheng
- 例子是展示 指令
ADD R0, [6] - 指令功能:把 R0 存储的内容,加上存储器地址为6的存储单元的内容,然后把结果存放在 R0 中
指令 ADD R0, [6] 全部步骤详解:
- 取址
- 控制器中:PC -> 内部总线 -> MAR
- 控制器中的 MAR -> 地址总线 -> 存储器中的 MAR
- 控制器具发出信号:Read,经过 控制总线 传递给存储器
- 存储器:(控制逻辑操作下),找到 MAR 存放的地址,然后把内容取出来,送到 存储器的 MDR
- 存储器:控制逻辑,给控制总线反馈状态: Ready
- 存储器的 MDR -> 数据总线 -> 控制器的 MDR
- 控制器中:MDR -> 内部总线 -> IR
- PC 寄存器自增更新
- 译码
- IR -> 指令译码
- 电路切换到对应的控制状态
- 执行
- IR 发现需要读取
[6]对应的数据, - 过程与步骤1 的取址几乎一样,最后 MDR -> 内部总线 -> Y
- R0 -> 内部总线 -> X
- ALU 执行➕
- IR 发现需要读取
- 回写
- Z -> 内部总线 -> R0
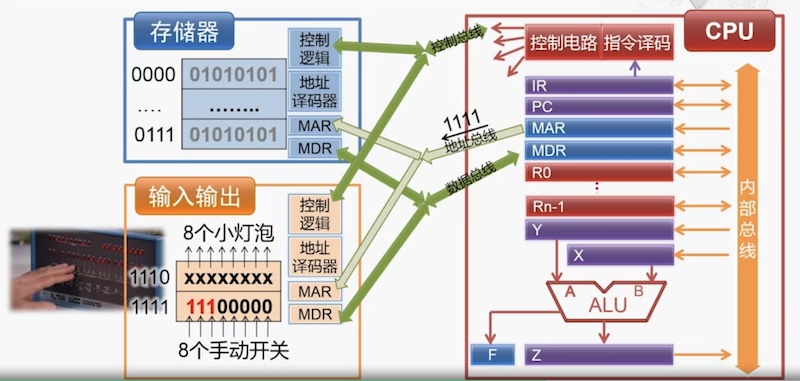
IO 设备(现代往往把 输入设备 和 输出设备 划在一起,例如硬盘)
- 如何在上面这套流程中加入 IO 设备呢?
- 入如下图所画,在各种总线上加上 IO 设备
- 旧的计算机,对于各种设备,都在主板上有的接口和芯片(例如网卡、声卡、打印机、耳机、显示器)
- 现代计算机,把各种输入输出设备都统一用 南桥芯片 来管理。不过图形计算比较复杂,还是用独立的显卡来处理。
南北桥结构的演变
演变1
- CPU 通过 北桥 来访问 存储器
- CPU 担任 CA、CC 功能(计算器和控制器)
- GPU 也有 CA、CC 功能
- 直接从硬盘启动时十分复杂的,用 BIOS 来检查主板设备和启动第一条指令。BIOS 是通过 南桥 连接的
演变2
- CPU直接控制主存
- CPU加上直接连接显卡
- 北桥消失,功能拆给CPU和南桥
更多的演变:
- 把所有的组件整合到单一芯片的集成电路上
- 手机、平板电脑等
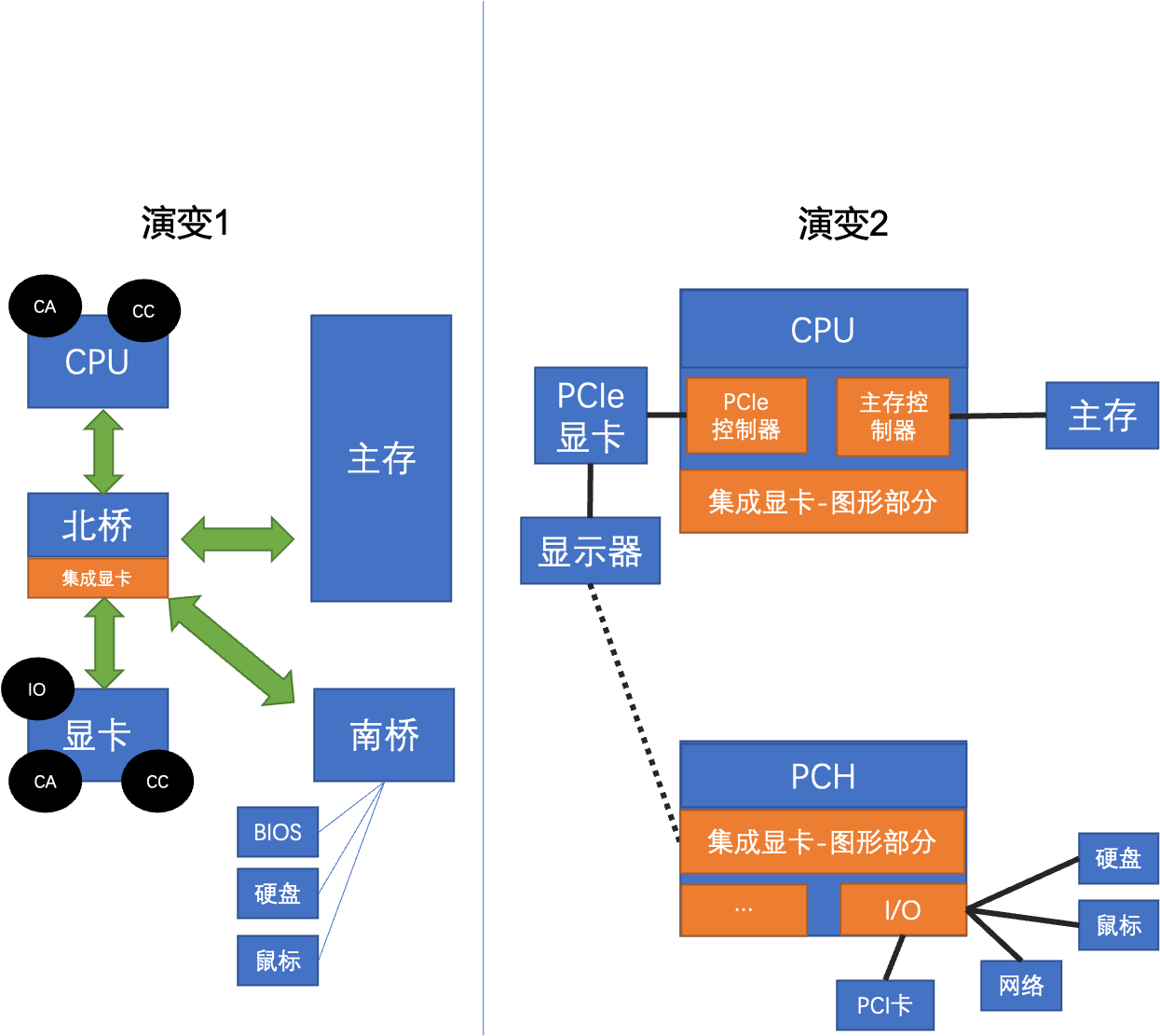
这种演变得益于芯片技术的进步(摩尔定律)
计算机指令
设计一套简单的指令
- 我们需要哪些指令?
ADD R, M: 把 寄存器 R 中的内容,与 存储器 M 中的内容相加,然后把结果存入 RLOAD R, M: 把 M 中的内容装入 RSTORE M, R: 把 R 中的内容存入 MJMP L: 转入 L 指向的存储器中
- 设计指令本身的格式呢
- 每条指令都是 2 个字节
- 第一个字节的高 4 位是操作码。例如
LOAD:0000; ADD:0001; STORE:0010; JMP:0011,这样我们可以共设计出 16 种操作类型 - 第一个字节的低 4 位是寄存器号,这样我们可以最多支持 16 个寄存器
- 第二个字节是存储单元地址,所以支持最大内存为
2^8 = 256个字节 - 举例来说,指令
ADD R2, [9],其指令对应的二进制为0001 0010 0000 1001
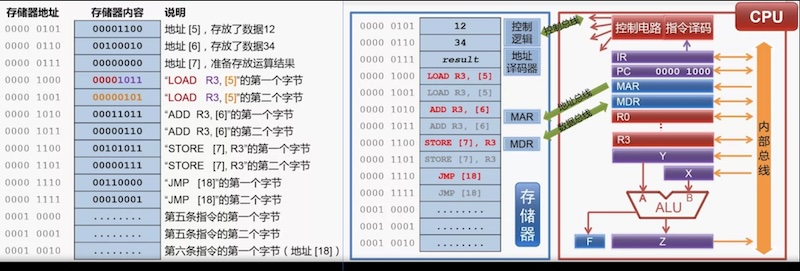
题目:使用以上的指令系统,写出一个功能:把 M1 中的内容和 M2 中的内容相加后存入 M3,然后转向 L 处的指令
指令为:
LOAD R3, M1
ADD R3, M2
STORE M3, R3
JMP L
假设 M1=5, M2=6, M3=7, L=18,那么机器语言为
0000 0011 0000 0101
0001 0011 0000 0110
0010 0011 0000 0111
0010 0000 0001 0010
以上程序在内存中,以及如何执行的,见于下图:
x86 体系结构
x86 体系主要分为 16位、32位、64位
- 16位的典型型号是 Intel 8086,8088,80186,80188,80286
- 32位的典型型号是 Intel 80386,80486
8086-16位CPU
基本情况
- 16 位 CPU
- 内部通用寄存器为 16 位
- ALU 是 16 位的
- 对外有 16 根数据线(MDR)和 20 根地址总线(MAR)。可寻址
2^20 = 1MB
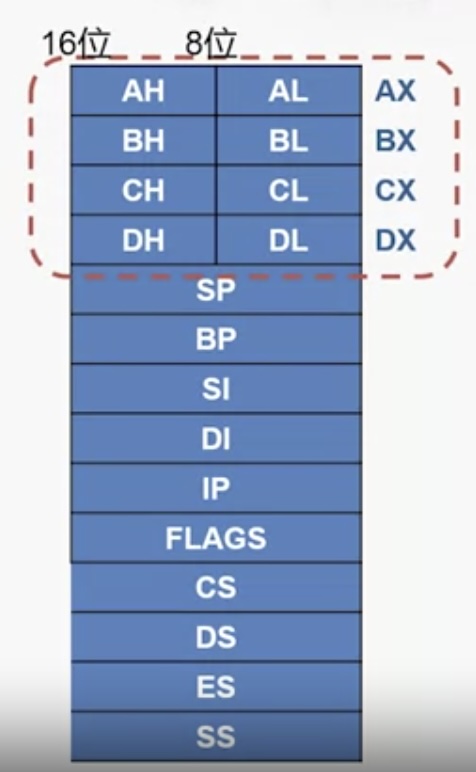
寄存器详解
AX、BX、CX、DX是通用寄存器,每个可以存放 1 个 16 位,或者 2 个 8 位- 早期约定:
AX存储乘除指令操作数(Accumulator) BX存储单元偏移地址(Base)CX计数(Counter)DX乘除中的部分积/被除数(Data)
- 早期约定:
SP、BP、SI、DI也是通用寄存器,在最早期版本各有任务,随着更新,它们也变成了通用寄存器IP对应“计算机结构简化模型” 中的 PC 寄存器- 程序员不能直接读写,只能用自增/转移/返回的方式影响,寻址能力为
2^16 = 64KB
- 程序员不能直接读写,只能用自增/转移/返回的方式影响,寻址能力为
FLAGS标志寄存器,就是上面 “计算机结构简化模型” 中的 F 寄存器。它存放了 2 类数据:1)状态标志,例如是否产生了进位,结果是否为零;2)控制标志,单步还是连续运行,是否允许响应中断。其 16 个二进制位意义如下:CS、DS、ES、SS(Code Segment, Data Segment, Extra Segment, Stack Segment) 是段寄存器- 8086 是如何寻址
2^20 = 1MB呢?- 采用段寄存器 +
IP - 举例来说,段寄存器左移 4 位,(可以看成“段基值”),得到一个 20 位的地址,加上
PC寄存器的值(可以看成“偏移量”)。两者通过 地址加法器 ,得到一个 20 位的地址,这就是物理地址。这个地址会发送到 地址总线
- 采用段寄存器 +
80386-32位CPU
基本情况
- 是 80x86 系列的第一款 32 位处理器
- 32位 ALU
- 32 位 寄存器
- 地址总线(MAR)是 32 位,可寻址
2^32 = 4GB内存空间
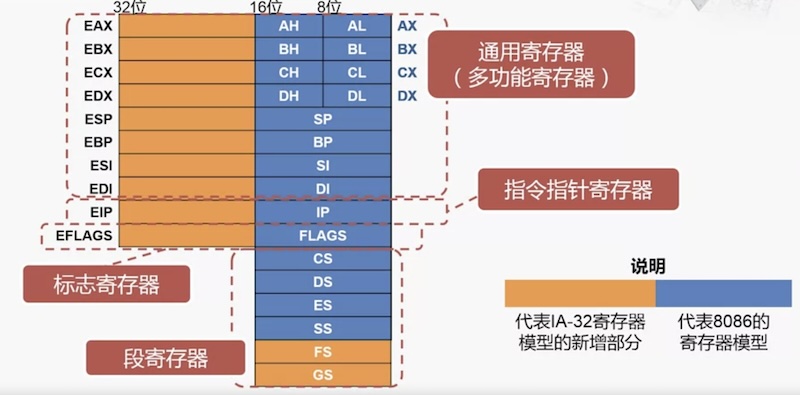
说明
- 这么做的原因是为了与 8086 向上兼容
- 新增2个段寄存器 FS,GS
x86-64 系列
基本情况
- 寄存器扩展到 64 位
- 新增了 8 个通用寄存器(共 16 个),新增的标记为 R8~R15

x86 指令
指令的分类
- 运算类。加减乘除、与或非
- 传送类。存储器到通用寄存器,通用寄存器到IO接口
- 转移类。条件转移、无条件转移、过程调用
- 控制类。暂停、清除标志位。
指令执行的结果
- 改变通用寄存器内容
- 改变存储器内容
- 改变标志位
- 改变外设端口内容
- 改变指令指针
- 其它
一、数据传输指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| MOV | 将数据从源操作数传送到目标操作数 | MOV dest, src | MOV EAX, EBX MOV EBX, 40:把40这个数字送入 EBX MOV ECX, [1000H] 把内存中的数据读入 EXC MOV [DI], AX 把 AX 写入 一个内存上,这个内存的地址存储在 DI 寄存器 MOV WORD PTR[BX+SI*2+200H], 01H 把一个双字节,存到某个内存单元,这个内存单元地址是计算得到的 |
| PUSH | 将操作数压入堆栈顶部 | PUSH src | PUSH EAX |
| POP | 从堆栈顶部弹出数据到操作数 | POP dest | POP EBX |
| XCHG | 交换两个操作数的值 | XCHG operand1, operand2 | XCHG EAX, EBX |
| LAHF | 加载标志寄存器的低8位到AH | LAHF | LAHF |
| SAHF | 将AH的值存入标志寄存器的低8位 | SAHF | SAHF |
| LEA | 计算源操作数的有效地址并存入目标寄存器 | LEA dest, src | LEA EAX, [EBX+ECX*4] |
| MOVSX | 带符号扩展传送 | MOVSX dest, src | MOVSX EAX, BL |
| MOVZX | 零扩展传送 | MOVZX dest, src | MOVZX EAX, BL |
| CMOVcc | 条件传送(当条件满足时) | CMOVcc dest, src | CMOVE EAX, EBX |
二、算术运算指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| ADD | 相加,并把结果存在 dst 寄存器 | ADD dst, src | ADD EAX, EBX |
| ADC | 带进位的加法, dst := dst + src + CF | ADC dst, src | ADC EAX, EBX |
| SUB | 执行减法运算 | SUB dest, src | SUB EAX, EBX |
| SBB | 带借位的减法 | SBB dest, src | SBB EAX, EBX |
| INC | 自加1 | INC operand | INC EAX |
| DEC | 自减1 | DEC operand | DEC EAX |
| MUL | 无符号乘法 | MUL src | MUL EBX |
| IMUL | 有符号乘法 | IMUL src | IMUL EBX |
| DIV | 无符号除法 | DIV src | DIV EBX |
| IDIV | 有符号除法 | IDIV src | IDIV EBX |
| NEG | 求二进制补码(取负值) | NEG operand | NEG EAX |
| CMP | 比较两个操作数,不保存结果,只影响标志位 | CMP operand1, operand2 | CMP EAX, EBX |
| CWD | AX扩展到DX | CWD | CWD |
| CDQ | EAX扩展到EDX | CDQ | CDQ |
| CQO | RAX扩展到RDX | CQO | CQO |
三、逻辑运算指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| AND | 按位与 | AND dest, src | AND EAX, EBX |
| OR | 按位或 | OR dest, src | OR EAX, EBX |
| XOR | 按位异或 | XOR dest, src | XOR EAX, EBX |
| NOT | 按位取反 | NOT operand | NOT EAX |
| TEST | 按位与,不保存结果,只影响标志位 | TEST dest, src | TEST EAX, EBX |
四、移位和旋转指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| SHL/SAL | 逻辑左移,右边补0 | SHL dest, count | SHL EAX, 1 |
| SHR | 逻辑右移,左边补0 | SHR dest, count | SHR EAX, 1 |
| SAR | 算术右移,(指的是保留符号的移位) | SAR dest, count | SAR EAX, 1 |
| ROL | 循环左移 | ROL dest, count | ROL EAX, 1 |
| ROR | 循环右移 | ROR dest, count | ROR EAX, 1 |
| RCL | 包括进位位的循环左移 | RCL dest, count | RCL EAX, 1 |
| RCR | 包括进位位的循环右移 | RCR dest, count | RCR EAX, 1 |
五、控制转移指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| JMP | 无条件跳转 | JMP label | JMP START |
| Jcc | 条件跳转,包括很多指令,见于下面的表 | Jcc label | JE LOOP_START |
| LOOP | 循环,使用计数寄存器 | LOOP label | LOOP LOOP_START |
| CALL | 调用子程序,保存返回地址 | CALL label | CALL SUB_ROUTINE |
| RET | 从子程序返回 | RET | RET |
| INT | 触发软件中断 | INT type | INT 21h |
| IRET | 从中断服务程序返回 | IRET | IRET |
Jcc 指令:
| 指令 | 功能 | 条件 |
|---|---|---|
| JC | 有进位时跳转 | CF = 1 |
| JNC | 无进位时跳转 | CF = 0 |
| JP/JPE | 奇偶标志为偶时跳转(Parity Even) | PF = 1 |
| JNP/JPO | 奇偶标志为奇时跳转(Parity Odd) | PF = 0 |
| JE/JZ | 相等或结果为零时跳转 | ZF = 1 |
| JNE/JNZ | 不相等或结果不为零时跳转 | ZF = 0 |
| JS | 符号标志被置位时跳转(负数) | SF = 1 |
| JNS | 符号标志未被置位时跳转(非负数) | SF = 0 |
| JG/JNLE | 有符号比较中,第一个操作数大于第二个操作数时跳转 | ZF = 0 且 SF = OF 这是因为 CMP 指令实际上是 SUB 操作但不保存结果,只更新标志位 |
| JL/JNGE | 有符号比较中,第一个操作数小于第二个操作数时跳转 | SF ≠ OF |
| JGE/JNL | 有符号比较中,第一个操作数大于或等于第二个操作数时跳转 | SF = OF |
| JLE/JNG | 有符号比较中,第一个操作数小于或等于第二个操作数时跳转 | ZF = 1 或 SF ≠ OF |
六、串操作指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| MOVS | 将数据从源字符串传送到目标字符串 | MOVSB(传送字节) / MOVSW(传送字,通常是2字节) / MOVSD(传送双字,通常是4字节) | MOVSB |
| CMPS | 字符串比较 | CMPSB / CMPSW / CMPSD | CMPSB |
| SCAS | 将累加器与目标字符串的数据比较 | SCASB / SCASW / SCASD | SCASB |
| LODS | 将源字符串的数据装载到累加器 | LODSB / LODSW / LODSD | LODSB |
| STOS | 将累加器的数据存储到目标字符串 | STOSB / STOSW / STOSD | STOSB |
| REP 前缀 | 当CX≠0,重复执行串指令,其不传入操作数,操作数存放在固定的寄存器,并且每次重复执行后做 CX-1 操作,直到CX=0;还可以设置 DF,来控制方向(来避免源串和目的串重叠) | REP instruction | REP MOVSB |
七、位操作指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| BT | 测试某个位的值,并将其存在 CF(标志寄存器中的进位标志) 中 | BT dest, bit_position | BT EAX, 2 |
| BTS | 测试某个位的值,并将其设置为 1,然后将原值其存在 CF 中 | BTS dest, bit_position | BTS EAX, 2 |
| BTR | 测试某个位的值,并将其设置为 0,然后将原值其存在 CF 中 | BTR dest, bit_position | BTR EAX, 2 |
| BTC | 测试某个位的值,并将其取反,然后将原值其存在 CF 中 | BTC dest, bit_position | BTC EAX, 2 |
| BSF | 找到最低位的1,返回其索引 | BSF dest, src | BSF EAX, EBX |
| BSR | 找到最高位的1,返回其索引 | BSR dest, src | BSR EAX, EBX |
| SETcc | 根据条件码设置字节为0或1 | SETcc dest | SETZ AL |
八、标志控制指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| CLC | 清除进位标志(CF=0) | CLC | CLC |
| STC | 设置进位标志(CF=1) | STC | STC |
| CMC | 取反进位标志 | CMC | CMC |
| CLD | 清除方向标志(使其自动递增) | CLD | CLD |
| STD | 设置方向标志(使其自动递减) | STD | STD |
| CLI | 禁止硬件中断(IF=0) | CLI | CLI |
| STI | 允许硬件中断(IF=1) | STI | STI |
九、系统指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| HLT | 停止处理器执行,直到收到中断 | HLT | HLT |
| NOP | 空操作,不执行任何操作 | NOP | NOP |
| WAIT | 等待处理器的忙标志被清除 | WAIT | WAIT |
| LOCK 前缀 | 用于在多处理器环境下,确保指令的原子性 | LOCK instruction | LOCK INC [EBX] |
| CPUID | 获取CPU的特性和功能信息 | CPUID | CPUID |
| IN | 从I/O端口读取数据 | IN accumulator, port | IN AL, DX |
| OUT | 向I/O端口写入数据 | OUT port, accumulator | OUT DX, AL |
十、浮点运算指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| FLD | 将浮点数装载到浮点堆栈 | FLD src | FLD [EBX] |
| FST | 将浮点堆栈顶部的值存储到指定位置 | FST dest | FST [EBX] |
| FADD | 浮点加法运算 | FADD src | FADD ST(0), ST(1) |
| FSUB | 浮点减法运算 | FSUB src | FSUB ST(0), ST(1) |
| FMUL | 浮点乘法运算 | FMUL src | FMUL ST(0), ST(1) |
| FDIV | 浮点除法运算 | FDIV src | FDIV ST(0), ST(1) |
| FCOM | 比较浮点堆栈顶部的两个值 | FCOM src | FCOM ST(1) |
| FCHS | 改变浮点堆栈顶部值的符号 | FCHS | FCHS |
十一、SIMD指令(是一种并行处理技术)
SIMD 指令通过在单个指令中指定多个数据元素的位置,允许处理器在一个指令周期内对这些数据元素执行相同的操作。在进行向量运算时,大大减少指令数量,提高执行效率。
- 有些高级语言,编译器能够自动识别数据并行性,并优化位 SIMD 指令。例如 GCC 和 Clang 都至此自动向量化优化
- C/C++ 的 intrinsics 也提供了 SIMD 指令集接口
- Rust编译器也能自动优化,也可以用
std::arch, std::simd访问 SIMD 指令
| 指令类别 | 功能 | 示例 |
|---|---|---|
| MMX 指令 | 处理并行整数运算,用于多媒体运算 | PADDW MM0, MM1 |
| SSE, SSE2, SSE3 | 并行浮点运算 | ADDPS XMM0, XMM1 |
| AVX 指令 | 扩展SSE,支持更宽的寄存器(256位、512位) | VADDPS YMM0, YMM1, YMM2 |
十二、其他指令
| 指令 | 功能 | 语法 | 示例 |
|---|---|---|---|
| XLAT | 根据累加器的值在查找表中检索数据 | XLAT | XLAT |
| BOUND | 检查操作数是否在数组边界内 | BOUND reg, mem | BOUND EAX, [EBX] |
| ENTER | 为过程建立栈帧 | ENTER nest_level, frame_size | ENTER 0, 10h |
| LEAVE | 从过程栈帧中退出 | LEAVE | LEAVE |
| UD2 | 执行时导致无效操作码异常 | UD2 | UD2 |
MIPS 体系结构
MIPS(Microprocessor without Interlocked Piped Stages),指导思想是减少指令的类型,降低指令的复杂度,以避免流水线上的互锁,进而提升性能(A simper CPU is a faster CPU)。例如,同样的功能,MIPS 的指令可能是5倍,但如果其执行速度是 10 倍,就仍然可以提升性能。
- RISC(Reduced Instruction Set Computer,精简指令计算机),相比之前的是 CISC(Complex instruction Set Computer,复杂指令系统计算机)
- MIPS 处理器广泛应用于:数字电视、机顶盒、蓝光播放器、游戏机、网络设备
- MIPS I,MIPS II(R2000,R3000) 是 32 位。1992年,扩展到 64 位(R4000,R8000)
- 主要特点:
- 固定了指令的长度,固定为 32bit,从而简化了从存储器取指令的操作
- 简化了寻址模式,使指令变多,但是 CPU 工作变少
- 指令数量少,指令功能简单,指令执行简化,一条指令只完成一个操作。从而可以优化并行的性能
- 只允许 LOAD 和 STORE 访问存储器
- MIPS 通用寄存器有 32 个,每个 32bit,且非常规整(相比于x86)
一些 MIPS 指令
- 算术运算(都是把结果存入 a)
add a, b, c,而addu a, b, c溢出不报错- 还有对应的 I 指令,
addi a, b, (-50)执行的是b = a + (-50)操作,;addiu对应“溢出不报错”版本。 sub a, b, c,而subu a, b, c溢出不报错mul a, b, cdiv a, b, c
- 逻辑运算
and a, b, cor a, b, c- 也有 I 型指令
andi a, b, imm
- 移位
sll a, b, csrl a, b, c
I 指令中的 immediate 是 16bit,而 ALU 是 32 位的,因此计算之间还有个补位操作,补位操作根据不同的运算还有区别。例如算术运算会根据补码原理把首个数字复制 16 次放到高位,而逻辑运算则是在高位补 16 个 0
MIPS 指令格式,从指令的分类上分为3类:R型,I型,J型。从功能上分为3类:运算指令、访存指令、分支指令:
| R型(Register,寄存器型) | I型(Immediate,立即数型) | J型(Jump,无条件转移) | |
|---|---|---|---|
| 运算指令 | add,sll 等 | addi,slti | / |
| 访存指令 | / | lw, sw | / |
| 分支指令 | jr t0 |
beq t0, t1, addr |
j addr |
R型指令 格式:
| opcode | rs | rt | rd | shamt | funct |
|---|---|---|---|---|---|
| 6-bit | 5-bit | 5-bit | 5-bit | 5-bit | 6-bit |
| 指令类型 R型指令为全0 |
第一个源操作数的寄存器序号 5-bit正好表示32个寄存器 |
第二个源操作数的寄存器编号 | 结果存放在的寄存器编号 | 移位操作的位数 非移位指令全0 |
指令类型 与 opcode 一起判断其类型 |
I型指令(有立即数就只能用 I 型指令),立即数常大于 31,因此不能复用 R 型指令,而是使用 16bit 来存放立即数:
| opcode | rs | rt | immediate |
|---|---|---|---|
| 6-bit | 5-bit | 5-bit | 16-bit |
| 源操作数的寄存器编号 | 结果的寄存器编号 | 对于访存指令,可以访问 ±32k 空间 对于运算指令,支持 16bit 数 |
条件分支指令也是 I 型,CPU会判断 rs 是否等于 rt,如果是,则跳到 immediate
- 这种设计避免了指令之间的互锁,例如 x86 的条件转移依赖于标志位,而标志位依赖于前一条指令的结果
- immediate 只有 16bit,如何充分使用呢?
- MIPS 的命令都是 32bit(4Bytes) 的,因此可以 4个字节为一个单位,这样就可以扩大寻址范围,到 ±128k。
- 这样的话,寻址实际上用的是
immediate × 4(也就是immediate <<2) - 因此,如果分支条件不成立,执行
PC = PC + 4;如果分支条件成立,执行PC = (PC + 4) + (immediate * 4)
J型指令(无条件转移):
| opcode | address |
|---|---|
| 6-bit | 26-bit |
目标地址的计算方法:PC = [(PC+4)[32..28] , address, 00],
- 目标地址范围
±2^28 bytes = ±256MB - 如何达到更远的地址?两次调用 J 指令,这要求把第二个 J 指令放到远处作为跳板;或者新增一种 R 型指令,把目标地址放入寄存器中
算术逻辑单元 ALU 的电路实现
这里以 MIPS 为例(MIPS 指令参见上面小节)设计 ALU 。
上面章节列了一些 MIPS 指令的功能,还写了这些指令使二进制位变化的结果。
这里从物理层面讲解其是如何能够达成这些变化的
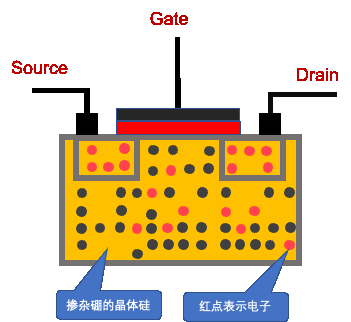
MOS 晶体管
MOS 晶体管(Metal-Oxide-Semiconductor,金属-氧化物-半导体)
MOS晶体管有两种
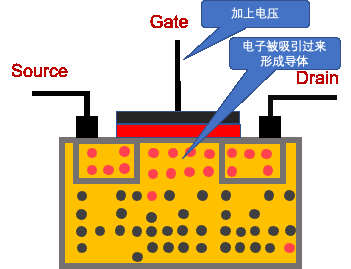
- N-MOS。 当 Gate 连接高电平时,Source 和 Drain 是导通的;当 Gate 连接低电平时,Source 和 Drain 是不导通的。
- P-MOS。 与 N-MOS 相反,当 Gate 连接高电平时,Source 和 Drain 是不导通的;当 Gate 连接低电平时,Source 和 Drain 是不导通的。
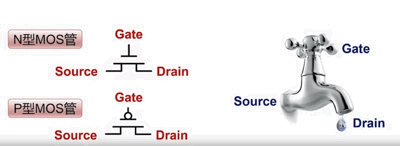
以上介绍了 MOS 的功能,那么它是如何设计的呢?
加上电压后,形成导体(通路)
下面看看如何用这两种晶体管构建一些 门电路
门电路
非门
非门的真值表:
| A(输入) | Y(输出) |
|---|---|
| 0 | 1 |
| 1 | 0 |
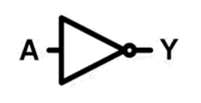
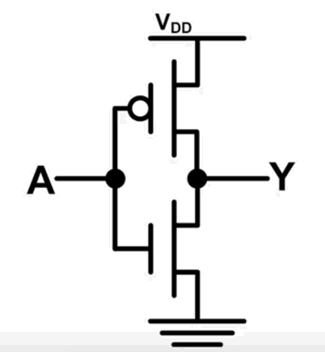
(自行分析一下,A 为 0 或者 1 的时候,电路的状态)
与非门
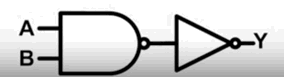
与非门 NOT (A AND B),比 与门 电路要简单很多,因此先设计与非门,然后用 与门 = 非与门 + 非门 来实现 与门
与非门的真值表:
| A(输入) | B(输入) | Y(输出) |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
与非门符号:

与非门电路:
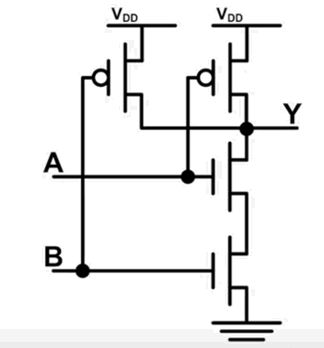
与门
与门符号:
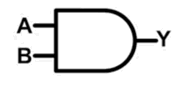
与门电路:
或门
或门的真值表:
| A(输入) | B(输入) | Y(输出) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
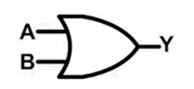
(没找到电路图,它是利用 A OR B = NOT ((NOT A) AND (NOT B) 即可想到,在与非门的输入A、B前各加一个非门,即可得到一个或门)
异或门
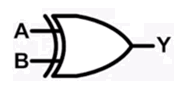
寄存器的物理实现
例如,一个 32 位的寄存器,其中包含 32 个基本存储单元,这个存储单元叫做 D触发器(D flip-flop,DFF)。
D触发器也是由逻辑门组成的(电路图不写了),其符号表示:
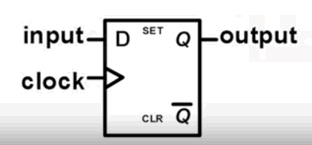
功能:
- 在时钟 clock 的上升沿,采样 D 的值,并将其传输到 Q,其余时间保持 Q 的值不变
- 用照相机的例子形象理解。时钟 clock 的上升沿:是按动快门的动作,每个动作0.1秒。照相机在按动快门时,对景色采样,并输出出来。不按动快门时,保持输出不变。

上图说明了:每个时钟周期,只向后传递一格
如果把电平时序画出来,如下:
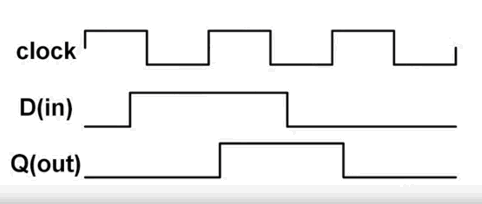
(可以分析一下,时钟上升沿和其它的情况,Q 是如何变化的)
寄存器堆和存储器
把 32 个寄存器看成一个整体,其输入输出如下:
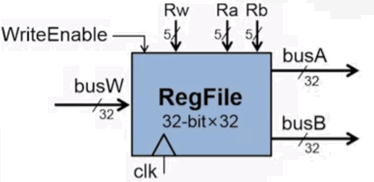
组成部分
- 内部是 32 个 32 位寄存器
- 两读一写:可以同时读两个寄存器,写入一个寄存器
- 读:Ra Rb 都是 5bit,用来指定要读的寄存器编号。可以同时读两个。读操作不受时钟影响,只要改变 Ra 和 Rb,那么 BusA 和 BusB 的数据就立即会变成对应的寄存器值
- 写:Rw 用开指定要写入哪个寄存器。BusW 指定了写入的值。WriteEnable=1 时才允许写。只有时钟上升沿才会写入。
存储器:底层原理类似于寄存器堆,其结构在上面的简化模型中有
逻辑运算的电路实现
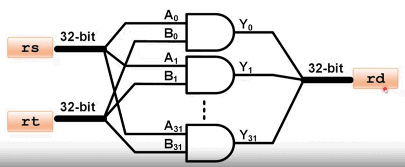
与运算 AND rd, rs, rt:
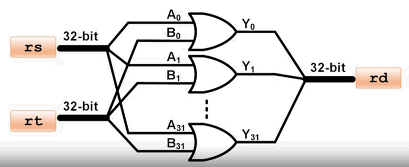
或运算 OR rd, rs, rt:
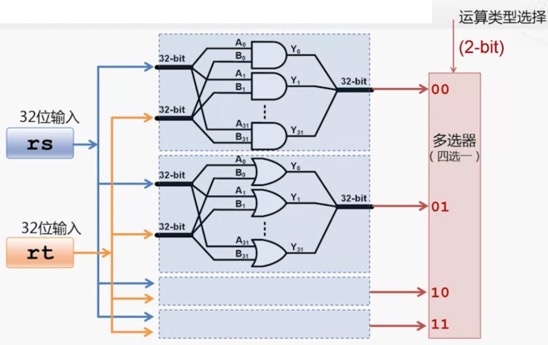
还包括其它的运算
那么,如何让 ALU 同时支持多种运算呢?
- 用并联的方式,把输入并联起来
- 同时通过所有的运算模块
- 也就同时输出所有运算的结果
- 在末尾加上一个 多选器,用来选取想要的结果
- 这个多选器也是由多个门组成的
- 这个多选器,对应的是上面模型机中的“控制电路”(的一部分)
下图表示支持 4 种运算的 ALU,那么多选器也就用 2-bit 来表示
加法器的电路实现
先分析二进制位的每一位如何加的
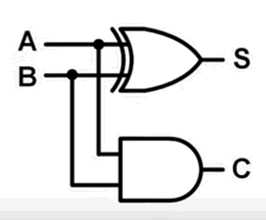
如果不考虑前一位的进位,某一个二进制位相 A + B 结果如下:
| A | B | S(和) | C(向下一位的进位) |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
分析上表发现,S = A XOR B, C = A OR B,于是可以设计出电路图(叫做 半加器(Half Adder)):
现在我们希望设计一个 全加器,它可以考虑前一位的进位,也就是计算 A + B + C_in,立即想到,全加器用两个半加器串联得到
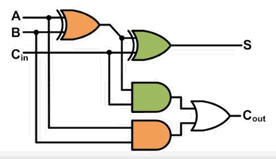
现在我们希望设计一个多bit 的加法器,以 4-bit 为例,把4个全加器串联起来

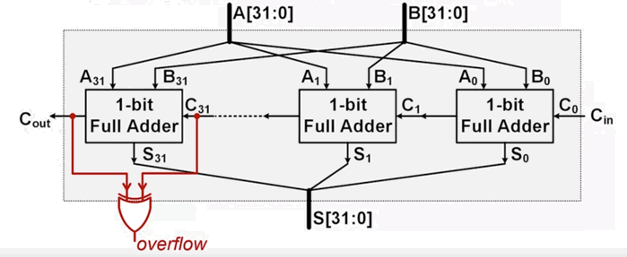
(如果是 32-bit 的,就串联32个全加器)
加法器的 溢出 问题。两种情况
- 无符号数加法的溢出:
- 定义:当两个无符号数相加的结果超过了加法器的最大表示范围时,就会发生溢出。这时候 CPU 给出的结果是是真实结果取模
- 示例:假设使用4位二进制表示无符号数,最大值为15(即1111)。如果将两个数相加,例如
1111 (15) + 0001 (1) = 1 0000 (16),结果1 0000需要5位表示,但加法器只能处理4位,因此发生溢出。
- 有符号数加法的溢出:
- 定义:在使用补码表示有符号数时,当两个正数相加得到一个负数,或两个负数相加得到一个正数时,就会发生溢出。
- 示例:使用4位补码表示有符号数,范围为-8(1000)到+7(0111)。例如,
0111 (+7) + 0001 (+1) = 1000 (-8),结果本应是+8,但由于超出表示范围,错误地表示为-8,发生溢出。
溢出的检测 CPU 用 OP(寄存器中的溢出标志,Overflow Flag)来检测溢出情况。加法器在执行运算后会根据结果自动设置或清除该标志位:
- 无符号数加法:最高位加法电路产生了进位,则设置溢出标志。
- 有符号数加法:如果两个操作数的符号相同,但结果的符号与操作数不同,则设置溢出标志。或者:“最高位的进位输入” 不等于 “最高位的进位输出” 表示发生了溢出,在电路上表示就是加一个“异或门”
如何处理溢出
- x86 :把溢出标志写入 OP
- MIPS:
add发生溢出时触发中断和异常。addu则不检测溢出
减法器的电路实现
考虑到 A - B = A + (-B)。如果我们能设计一套表示负数的二进制系统,并且保证其遵守加法运算的规则,那么减法就可以复用上面设计好的加法器。这套系统叫做 补码。
- 首先规定全 1 的二进制表示 -1,也就是
1111 1111 = -1 - 然后得出
X + (~X) = 1111 1111 = -1 - 所以
-X = (~X) + 1,也就是说,任意负数的补码可以用正数的“按位取反,然后加1”得到 - 因此,我们实现减法器为
A - B = A + (~B + 1)
现在我们设计减法器的电路
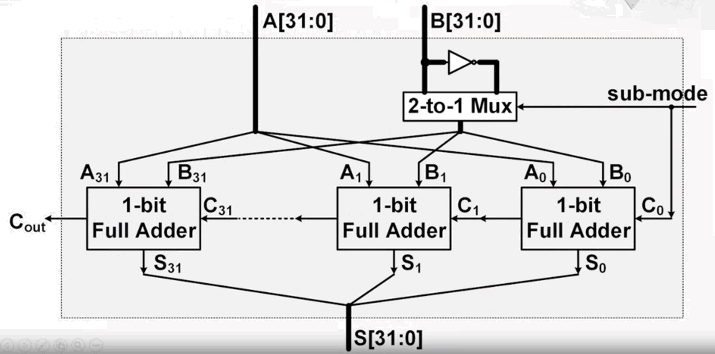
说明
- 在加法器的基础上加入了一个选择模块
2-to-1 Mux - 当计算加法的时候,
2-to-1 Mux选择左边线路的数据,整个电路与加法器一致- 当计算减法的时候:
- 数据会先通过非门(就是取反)
- 然后
2-to-1 Mux选择右边线路的数据(也就是取反后的数据),传给下面的加法器 - C0也会被传入1
- 以上就实现了“取反加1”的操作,然后通过加法器得到结果
- 当计算减法的时候:
加法器的性能优化
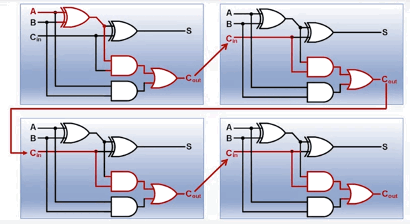
上面我们设计的加法器叫做 行波进位加法器(RCA),其特点是
- 32个全加器是串联的,每个全加器的进位输出
C_out,连接下一个全加器的进位输入C_in - 每个全加器都要等待上一个全加器计算完成,并给出进位信息,才能开始运算。
- 因此信息就像一个行波一样
- 假设每个门的延迟是
T,那么总的延迟就是(2n+1)T - 下图画了 4-bit 加法器的串联情况:
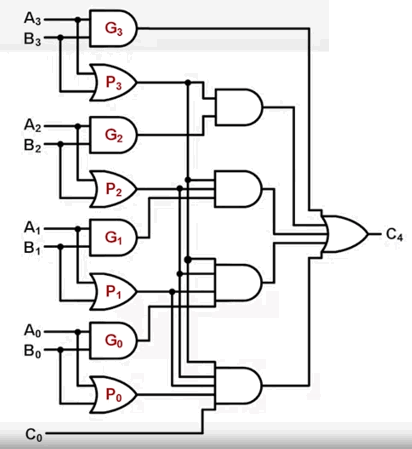
进位值 C 能否快速计算得到呢?注意到进位值 C 的某个递推公式,就可以这样设计电路:超前进位加法器(CLA) :
说明
- 计算进位数只需要通过3个门电路,因此整个加法器只需要4个门电路。并且无论是多少位的加法器,都只要4个门电路。而不是像 RCA 一样需要
2n+1个。例如 32 位加法器,RCA 需要 65 个门延迟,CLA 需要 4 个门延迟。 - 然而,对于 32位 加法器,电路实现十分复杂,因此一般做个分段,用 3个 8-bit CLA 串联,形成一个 32 位加法器。
乘法器的电路实现
先看一下我们是如何手算乘法的:

我们发现一个规律:
- 如果乘数的某一位是 1,那么直接把被乘数抄下来;如果乘数的某一位是 0,那么抄下全 0 即可。
- 这里使用二进制,大大简化乘法过程。如果用 10 进制,还涉及到九九乘法表。(冯诺依曼在关于EDVAC的报告草案中,分析为什么使用二进制,其重要原因就在这里)
- 综合来说,二进制的乘法,就只需要移位和加法即可实现,下面设计算法
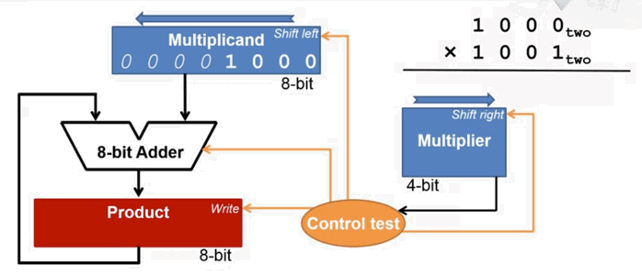
乘法算法实现
- 初始化:被乘数寄存器 A,乘数寄存器 B,结果寄存器 P 初始化为 0
- 判读 B 的最低位,如果是1,执行
P = P + A;如果是0,不做操作。转到下一步 - A 左移一位,B 右移一位。
- 判断循环次数是否为 n 次(例如 32 位就是 32 次),如果是,则结束循环;否则回到步骤 2
根据上面的算法步骤,硬件实现如下:
乘法器的优化
时间上的性能优化
- 分析时间消耗:每次循环,A 左移需要 1T,B 右移动需要 1T,加法
P=P + A需要 1T。 - 优化:加法、左移、右移可以并行起来,在同一个时钟周期同时完成。性能提升了3倍
晶体管的数量优化
- 分析浪费:
- Multiplicand:只有 4 位,却占了 8 位,这是因为随着循环迭代,会左移 4 次
- Multiplier:占了 4 位,但是随着循环迭代,其实际占用依次减一
- Product:一开始数量只有 4 位,随着循环迭代,其实际占用依次加一
- 8-bit adder:8位宽,但是实际上只进行了 4 位的加法运算
- 优化:
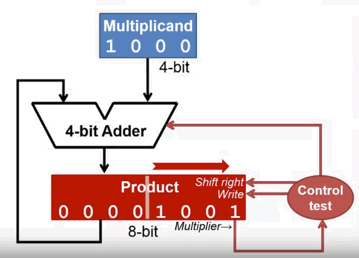
- Multiplicand:原本是 8-bit ,改为 4-bit,并且取消向左移位功能。改为让 Product 右移。
- 考虑到 Product 和 Multiplier 都会右移,把 Multiplier 寄存器取消,其值初始化到 Product 的低位。这样就可以节省空间,并且同时右移
- 由于把 Multiplier 寄存器取消了,其值放在了 Product 的低位,原本连接在 Multiplier 末尾的 控制逻辑(Control test),改为连接到 Product 的末尾。
优化后的电路:
除法器的电路实现
先看除法是如何计算的
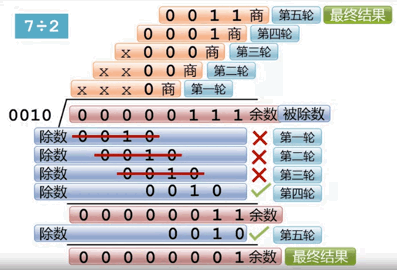
算法步骤(假设被除数是 8bit,除数是 4bit):
- 准备
- 需要一个 8bit 余数寄存器,初始化为 被除数。
- 需要一个 8bit 寄存器,把除数放入它的高4位,它要有右移的功能。
- 需要一个 4bit 商寄存器,初始化为0,它要带左移功能。
- 需要一个 8bit ALU,它支持加法和减法运算
- 检查
余数 = 余数 - 除数。 - 判断余树,如果 ≥0 ,则商左移一位,并把末尾设定为1;否则回退(执行
余数 = 余数 + 除数),然后商左移1位,并把末尾设定为0 - 除数右移一位
- 如果执行了 9 次,则结束,否则回到 步骤 2。(如果是除数 32bit,则执行 33 次后结束)
电路设计如下:
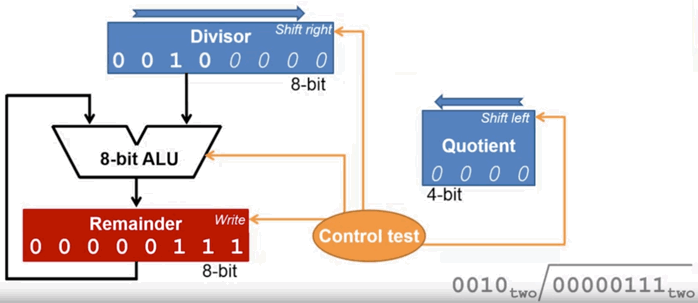
除法器的优化。对于 32 位 CPU 分析:
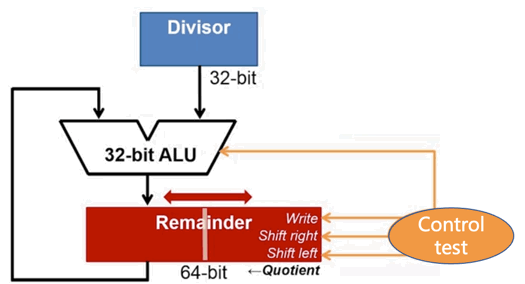
- 除数寄存器只用了左边的一半,它在迭代中逐步右移
- 商寄存器初始是空的,它在迭代中逐步左移填满
- 余数寄存器初始是满的,但是迭代过程中有意义的位从左到右逐步减少。
- 另外,对于 32 位 CPU,我们希望被除数是 64位的(两个寄存器组合使用),希望 ALU 的加法器和减法器仍然保持 32 位。
空间上的优化的结果:
时间上的优化:乘法天然可以分解多部分,并行做乘法,最后加起来。这就可以很好的做并行。
处理器
上面分别拆分并从电路出发,详细解释了这些部件:
- ALU,逻辑运算器、算术运算器
- 寄存器,两读一写
- 存储器,一读一写
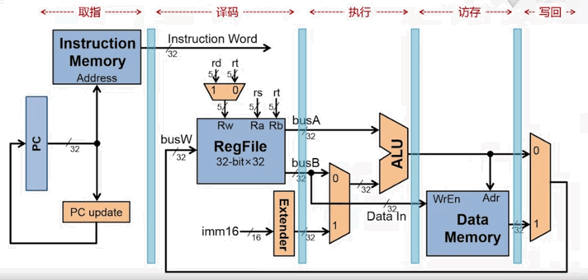
这些元件如何组合起来,使其可以完成多种指令(例如各种运算、访存、跳转),还需要设计一些电路。参考 单周期处理器
- 组合时,很多地方都要添加 1bit 的控制信号,用来控制某个部件选择哪一个值作为输出。
- 这就需要设计一个控制电路,来把指令中的
opcode(6bit) 和funct(6bit) ,“翻译成” 控制电路的状态。 - 假设 1bit 的控制开关有 6 个,问题就变成了:如何把 12bit 的向量,映射为 6bit 的向量。解出这种映射关系后,就可以用各种门的组合来实现它了。
流水线处理器和超标量流水线
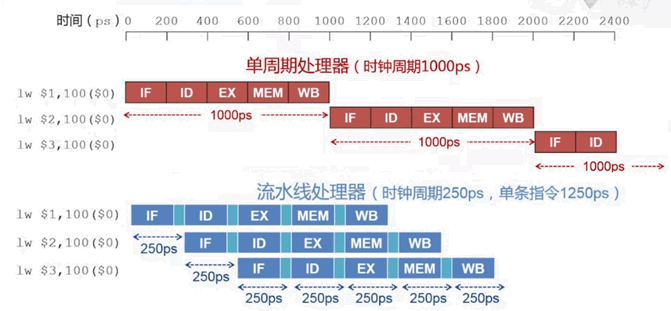
我们分析一条指令的执行过程,发现:
- 每条指令都涉及到这么几步:取址、译码、执行、访存、写回
- 这几步用到的硬件是不同的
- 因此可以把他们改造为流水线,而不是等待上一条完全执行完毕才进行下一段
- 为此,需要在每一步中间添加 流水线寄存器,以保证数据传递的正确性。这额外花费一些时间
- 这提升了整个程序的执行速度,但是降低了单条指令的处理速度,所以本质上是提高 指令的吞吐率
优化前后的性能比较:
流水线的优化
- 以上假定了每个阶段的耗时都一样,实际上是不一样的,这就是 不平衡的流水线,它。假设单周期处理器,处理单条指令时间消耗是
1s + 1s + 3s + 1s +1s = 7s,那么流水线处理器,处理单条指令的时间消耗是3s * 5 = 15s,多条指令也没有快多少 - 解决:把消耗较多的步骤继续切分,作为独立的步骤加入流水线。
- 超级流水线。就是把五级流水线继续细分为更多的阶段,从而增加流水线的深度。这进一步提升了时钟频率和指令吞吐,
- 流水线深度也并非越多越好,原因:1)阶段划分越细、深度越高,也就意味着 流水线寄存器 越多,它在时间消耗中的占比也就越来越多。级数越多,同时在流水线上的指令也就越多、之间的关系也越复杂,这带来了一些负面影响。
- 历史。MIPS 设计之初考虑了流水线,因此率先提出流水线结构。因为 x86 复杂,很长一段时间后,1995年 x86 才实现了流水线(Pemtium Pro),它借用了 RISC 相关技术。2004年前后有“频率大战”,是因为消费者只能看懂时钟频率,而深度越高时钟频率也越高,Pemtium 4 达到顶峰的 31 级。之后回落,现代的流水线一般是十几级。
超标量流水线,把流水线上一些步骤,设定为多个模块并行。

多核CPU,每个核里有一个超标量流水线
流水线冒险
冒险 Hazard:在流水线处理器中,阻止下一条指令在下一个时钟周期开始执行的情况
- 结构冒险:所需硬件正在为之前的指令工作
- 问题:“取址”和“访存”都需要存储器的读操作,就发生了结构冒险
- 解决方法1:流水线停顿(stall),在原来的位置放入空泡(bubble),空泡经过流水线时不改变任何机器状态。但如果下一个指令还是有结构冒险,就继续停顿。
- 解决方法2:把指令和数据放入不同的存储器(CPU的一级缓存),避免同时读。
- 问题:“译码”需要读寄存器堆,“写回”需要写寄存器堆,就发生了结构冒险。
- 解决方案:使寄存器堆可以在同一个时钟周期读和写。在一个时钟周期前半部分写,后半部分读。
- 数据冒险:需等待之前指令完成数据读写
- 问题:连续的两条指令是
add t0, s1, s2; sub s3 , t0, s4,第二个指令需要等待第一个指令把 t0 算出来,并且写回,才能够执行。
- 问题:连续的两条指令是
- 控制冒险:需要根据之前的值决定执行什么操作
数据冒险 的解决方法
- 解决方案1:代码层面解决,代码中插入 nop(nop是不做任何操作)。但是问题是插入几个 nop?不同的 CPU 不一样,这就违反了“软件屏蔽硬件细节”的原则
- 解决方案2: 流水线停顿(stall),类似上面“结构冒险”中的 stall。译码阶段就先判断会读/写的寄存器编号,从而判断是否发生数据冒险。然后插入 bubble。
- 但是连续多条指令读写同一个寄存器的情况是频繁出现的,这个处理堆处理器性能影响很大。 - 解决方案3: 数据前递(Forwarding,有时候叫旁路 bypassing),上一条指令在计算之后,还没访存前,是存在 ALU 阶段的访存寄存器中的,那么下一条指令直接读入这个访存寄存器即可。
- 存在以上方法无法解决的数据冒险,例如先
load然后使用 load 后的寄存器来计算。这种情况就可以用 forwarding(访存阶段的流水线寄存器 到 ALU)+ bubble(一次) 方式解决
发生 控制冒险 后,会执行一些本不该执行的语句,需要重置其电路以消除影响。对性能的影响很大: 1)转移指令很常用,占比20%左右。2)现代处理器都是超标量、深度流水线(导致十几条指令不应该被执行)。这样看来,控制冒险的影响很大。
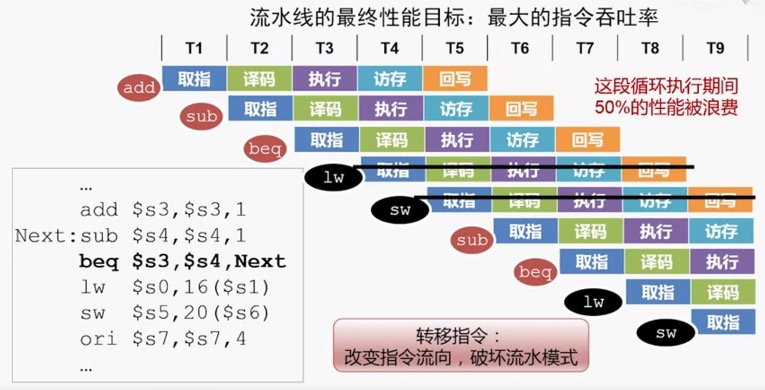
转移分为4种:无条件的直接转移、有条件的直接转移、无条件的间接转移、有条件的间接转移。
通过 forwarding + bubble 解决控制冒险:
| 无条件转移 | 有条件转移:需要判断是否转移 | |
|---|---|---|
| 直接转移:目标地址在取址时获得 | 命令:j addr 目标地址在取址时就可以获得,流水线无需停顿 |
命令:beq t0, t1, addr 虽然译码时可获得目标地址,但需要 ALU 判断是否转移,流水线停顿 2 个周期. 不过可以改造,在 ALU 之前加一个判断全等的电路,这样流水线停顿1个周期 |
| 间接转移:目标地址需要从寄存器取出 | 命令:jr t0,在译码阶段能获取目标地址,流水线需要停顿 1 个周期 |
延迟转移技术:用代码来解决控制冒险,把前面无关的代码放到转移指令之后(填充)
多级存储器
哪些组件有存储功能?CPU中的寄存器、主存、外部介质(硬盘之类的)
存储器的评价指标
- 非易失性,存储器断电不丢数据。
- 非易失:BIOS、硬盘。
- 易失:断电丢失。主存、CPU中的寄存器。
- 可读可写
- 随机访问 的性能是 O(1),与其位置无关
- 访问时间
- 容量
- 价格
- 功耗
评价一下
- CPU中的寄存器。访问速度极快,且近几十年提升巨大
- Disk,访问时间比CPU慢几百万倍,且随着时间提升不大。不过价格下降幅度很大。
- DRAM,两个指标都介于两者之间
- 但是 DRAM 速度仍然远远跟不上 CPU,那么在 DRAM 和 CPU 之间,放一个 SRAM(Cache)
DRAM
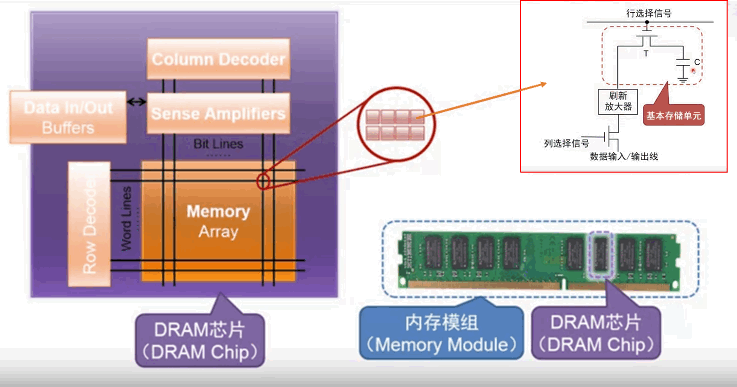
- 上图是一个 DRAM 芯片。一个内存条(内存模组)由一块电路板和几个 DRAM 芯片构成。多个 DRAM 是并行工作的,例如,每个地址同时传入到 8 个 DRAM,每个返回 8bit,它们组合返回一个 64bit
- 用电容存储数据。
- 电容存在漏电效应,因此需要定期刷新,用 刷新放大器。
- 断电易失
- 有一条行选择信号,有一条列选择信号,共同决定选择哪一个基本单元
- 现代 PC 大多用 DRAM 作为主存储器(内存),例如 SDRAM,DDR2 SDRAM,都是在 DRAM 的基本结构上做的升级。
SDRAM 的性能
- 时间顺序:
行地址 -(tRCD, Row to Column Delay)-> 列地址(CL)->(连续依次读出数据)数据1->数据2->数据3 - CPU 读取一个数据后,下次读取的数据,其行地址大概率一样。每次把整行读取出来,放到缓存区,下次直接从缓存区读取,这样可以省掉 tRCD。而如果下次读取不是同一行,则需要关闭行(行预充电,RAS Precharge),所用时间为 tRP
- 性能指标:tRCD、CL、tRP
Cache
SRAM
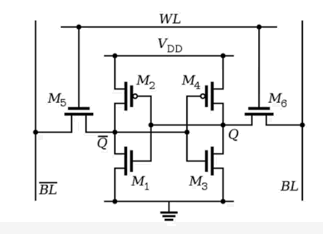
- 上图是一个 SRAM 芯片的一个存储单元,它用来存储 1bit。
- 通过 MOS 晶体管来存储数据
- 不需要行/列信号,
- 优点:速度快,晶体管远比电容快
- 缺点:集成度低,功耗高,价格高
- 现代 CPU 的高速缓存常用 SRAM
Cache 的理论基础:局部性原理
- “时间局部性”,最近被访问的,高概率再次被访问
- “空间局部性”,最近被访问的,高概率附近被访问
Cache:
- 保存最近频繁访问的数据,以及访问数据周围的数据块(Block)
- CPU 不直接访问主存,而是访问 Cache. 如果有数据(叫做 Cache 命中),则 Cache 返回数据;如果没有数据(叫做 Cache 失效),则 Cache 读取主存并返回数据
Cache 的写策略
- Cache 命中时的写策略
- 写穿透(Write Through):数据同时写入 Cache 和主存
- 写返回(Write Back):数据只写入 Cache,仅当数据块被替换时才将数据写回主存。(实现复杂,但性能高)
- Cache 失效时的写策略。
- 写不分配(Write Non-Allocate):直接把数据写入主存
- 写分配(Write Allocate):把数据所在块读入 Cache,然后把数据写入 Cache。(实现复杂,但性能高)
Cache 性能分解(读操作)
- 命中率:Cache 命中的概率
- 命中时间:从 Cache 中返回数据的时间
- 失效率:
1 - 命中率 - 失效代价:从主存读取数据,并返回数据
平均访存时间 = 命中时间 + 失效率 ✖️ 失效代价
Cache 失效原因
- 义务失效(Compulsory Miss)
- 第一次访问某个数据块
- 无法避免
- 容量失效(Capacity Miss)
- Cache 无法保存所有需要的数据块
- 解决方案:增加 Cache 容量
- 冲突失效(Conflict Miss)
- 多个存储器位置映射到同一 Cache 位置
- 下面是映射策略:
- 直接映射,把主存位置整除8,放入 Cache 对应的位置。实现简单,但是如果位置冲突的变量经常读入,就会不停的 Cache 失效
- 2路组 Cache/3路/4路,就是多n倍Cache,用来备用
- 全路组,实现复杂
- 设计 Cache 替换算法
- Random
- 轮转 Round-Robin
- 最近最少使用 LRU
还有:指令Cache和数据Cache要分开,否则数据密集型任务会很快占满 Cache,导致每次指令取址都有 Cache 失效
中断和异常
异常 的例子,发生溢出后怎么办?如果用固定的电路来处理就不灵活,那么可以转向地址0,在地址0放有修复指令。
- 也就是加一个电路:如果发生异常,则把 PC 置为0
- 中断 和 异常 这两个概念没有绝对的区分
只放在地址0是不够的
- 异常的情况有多个
- 处理1个异常需要多个指令
地址空间为 00000H-FFFFFH,共 1M 字节
- 其中 00000H-003FFH,(1kB),是中断向量表区,用来存放256个中断服务程序的入口地址(中断向量),每个中断向量有 4Byte,其内容包括段基值和偏移量。
- 000400H-FFFEFH,通用区,用来存放一般的指令和数据
- FFFF0H-FFFFFH,(16Byte) 初始化代码区
中断向量表哪来的?
- 实模式下,启动时,由 BIOS 写入到内存
- 保护模式下,在内存任意位置,其地址存放在 CPU 的 GDTR 寄存器中
中断的执行流程
- 关中断。不再接受其它外部中断请求。标志寄存器 IF 位,如果
IF=0,允许响应可屏蔽中断请求;如果IF=1,不允许响应可屏蔽中断请求 - 保存断点。中断出的指令压入堆栈
- 识别中断源。找到中断服务地址
- 保护现场。中断处的寄存器和标志寄存器的内容压入堆栈
- 执行中断服务程序。这时可以响应高优先级外部中断
- 恢复现场
一些中断类型
- 除法错误、溢出中断等
- 内部中断:单步中断,用来调试 CPU 的每一条指令都产生一个中断,并把寄存器的内容打印出来;断点中断;
一些功能可以调用中断
- BIOS 封装了一些 IO 设备的功能,例如显示、查看时钟,这样程序员可以不用关心硬件物理特性,即可用中断的形式调用一些功能。
输入输出设备
设备种类很多,因此设置一个专门设备(输入输出接口),来作为与 CPU 连接的中转站,输入输出接口的基本功能:
- 数据缓冲:解决CPU和外设之间的速度差距
- 协调和同步数据交换过程
- 信息格式转换,例如:模拟信号/数字信号,串口/并口
- 设备选择。例如多个硬盘
- 中断管理
- 可编程功能
IO 端口编址
- IO端口/存储器分开编址(x86)
- 直接寻址,最大端口号为 255。读入
IN AL, 80H,读出OUT 80H, AL - 间接寻址,允许端口号大于 255. 读入
MOV DX, 288; IN AL DX;,读出MOV DX, 288; OUT DX, AL; - 需要额外一个信号,区别这个地址代表的是存储器还是IO端口
- 优点:因为x86分开编址,且是变长指令,因此可以把IO指令设计的非常短,执行也就快;单独的IO指令,可读性强
- 直接寻址,最大端口号为 255。读入
- IO端口和存储器统一编址(ARM、MIPS)
- 优点:可以用访问存储器的指令来访问IO,而访问存储器的指令功能齐全;CPU内部只需要一套控制逻辑,这样内部电路简单,也减少了CPU的引脚数。
- 缺点:IO端口占用了存储器的地址空间(早期16位是个问题,现代64位不是问题);指令长度更长(对应分开编址的优点)。
IO控制方式
- 程序控制方式
- 无条件传送方式
- 假定外设一直是准备好的状态
- CPU直接与外设传送数据
- 不查询外设的工作状态
- 只适用于简单的外设
- 比喻:定了个外卖在校门口,然后不管校门口有啥,张嘴就吃。
- 程序查询方式
- CPU 不断查询外设状态(握手信号)。
- 输出过程:(仅为描述,因为还有个中间硬件输入输出设备)
- CPU 把数据输出,并且把写出状态置为有效
- 外设接受数据,然后返回一个接收成功的信号
- 在此过程中,CPU 循环查询这个接收成功的信号
- 输入过程
- 外设把数据发到数据线上,并且置“输入”信号为有效
- CPU 不停的检查“输入”信号,直到其为有效,这时把数据线中的数据读进来
- 缺点:查询外设占用大量时间
- 比喻:任务单上写满了“去校门口拿外卖”,于是不停的在寝室和校门口之间跑动,一天时间什么都不用干了。
- 无条件传送方式
- 中断方式
- 外设有数据传入时,向 CPU 发送中断请求。CPU 进入中断服务程序,这段程序检查发生了什么,然后执行数据传入。
- 优点:提高效率,能并行(CPU和外设并行);外设有申请服务的主动权;满足IO实时性要求
- 缺点:外设与存储器之间的数据交换仍由CPU承担,中断进入和退出也消耗资源,比程序控制方式的响应慢
- 比喻:做其它事情的同时等待外卖电话,接到电话后去拿外卖
- 直接存储器访问(DMA)方式
- 不通过 CPU 来搬运数据,而是用一个 DMAC 把数据从外设搬运到主存。搬运完成后,向 CPU 发送中断信号。这个期间,CPU 要设置详细信息:源地址、目标地址、待传送的长度。
- 现代的网卡、显卡等对传输率要求高的设备自带 DMAC
- 比喻:外卖是1吨书,那就需要一个搬家公司,让他们直接从门口搬到仓库,完事后搬家公司给我打个电话,通知搬运完成。
参考资料

一些图表参见:计算机结构.pptx
您的支持将鼓励我继续创作!
