【数据结构7】树理论篇、最小生成树
🗓 2021年01月02日 📁 文章归类: 0x80_数据结构与算法
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2021/01/02/tree.html
相关知识
- 二叉树:以及各种遍历算法
- 哈夫曼树与编码
- AVL树
- B树与B+树
- 前缀树
- 红黑树
- 线段树
树的基础定义
【定义】树:一个连通且无回路的无向图称为树。一个无回路的无向图称为森林。
假设T是一个有n个节点的无向图,那么以下6个命题等价
- T是一个树
- T是无环图,且有n-1个边
- T是连通图,且有n-1个边
- 任意两个节点之间有且只有一条路径
- T是无环图,且任意添加一条边都会产生环路
- T是连通图,但任意删除一条边都会把T变成两个连通分量
生成树
【定义】生成树 连通无向图G的生成树T是这么定义的:
$G=(V,E), T=(V,E_1), E_1 \subseteq E$ 且 $T$ 是树
(当然,如果G不是连通图,那么也不存在生成树)
【定理】 连通图至少有一个生成树。
【定义】最小生成树 T是G的生成树,如果G是加权图,$w(T)=\sum\limits_{e\in E_1} w(e)$,那么,使得$w(T)$最小的T,叫做最小生成树
Tree的相关定义
根节点:没有父节点的点
节点的度:某个节点拥有子节点的个数
叶节点:度为0的节点
分支节点:度不为0的节点
子节点
父节点
兄弟节点:共享同一个父节点的节点
树的度:所有节点的度的最大值
节点的层次:从根节点到某节点路径上的分支数,根节点的层次是0, 任意节点的层次=父节点的层次+1
树的深度:所有节点的层次的最大值。空树的深度是-1,只有一个根节点的树的深度是0
无序树:兄弟节点是无序的
有序树:兄弟节点是有序的。二叉树是一种有序树。
森林:m($m\geq 0$)颗树的集合叫做森林。一棵树的根节点有m颗子树,那么删掉根节点后,就变成包含m颗树的森林
对树进行删除、插入、搜索操作,最坏情况下复杂度为$\Theta(\lg n)$
Tree的代码表示
1. 用结构化数据存 Tree
1、父节点表示法
- 优点:寻找父节点方便
- 缺点:寻找子节点不方便
| 点 | 父节点 |
|---|---|
| 0 | -1 |
| 1 | 0 |
| 2 | 0 |
| 3 | 1 |
| … | … |
2、子节点表示法
- 子节点这个字段可以是一个 array
- 子节点这个字段也可以是展开后的单个 node
| 点 | 子节点 |
|---|---|
2.2、针对二叉树:
| 点 | 左子节点 | 右子节点 |
|---|---|---|
3、 父子节点表示法:既有父节点,又有子节点
4、 子兄弟表示法:既有子节点,也有兄弟节点
2. 链式存储
用指针指向子节点,大多数实现都是这种,见于代码。
3. 只针对二叉树:用 Array 存储
见于二叉树
二叉树
二叉树的定义
- 二叉树是一种
有序树,由一个根节点和两个互不相交的子二叉树构成,两个自子二叉树分别叫做左子树和右子树 - 满二叉树 :一颗二叉树上,所有分支节点都存在左子树和右子树,并且所有叶子节点都在同一层。深度d的二叉有 $2^d-1$ 个节点
- 完全二叉树:满二叉树去掉末尾k个节点
二叉树的性质
- 第i层上最多有$2^i$个节点
- 深度为k的二叉树,最多有$2^{k+1}-1$个节点
- 一个完全二叉树有n个节点,那么深度$k=\log_2(n+1)-1$
- 一个二叉树,度为0,1,2的节点数为$n_0,n_1,n_2$, 那么, $n_0=n_2+1$
- 一个具有n个节点的完全二叉树,如果从上至下和从左至右从0开始编号那么,对于序号为i个节点,有:
- 如果i>0,双亲节点序号是 (i-1)//2; 如果i=0,那么i是根节点,无双亲节点
- 如果2i+1<n,那么左子节点序号为2i+1; 如果2i+1>=n, 那么无左子节点
- 如果2i+2<n,那么右子节点序号是2i+2; 如果2i+2>=n, 那么无右子节点
二叉树遍历
规定 D,L,R 分别代表“访问根节点”,“访问根节点的左子树”,“访问根节点的右子树”,这样便有6中遍历方式:
LDR,DLR,LRD,RDL,DRL,RLD
因为先遍历左子树和先遍历右子树的算法很相似,所以研究这几种遍历方式:
前序遍历(DLR),中序遍历(LDR),后序遍历(LRD)
给定一个遍历序列并不能唯一决定一个二叉树,但给定一个二叉树序列的前序遍历序列和一个中序遍历序列,可以唯一确定一个二叉树。
Huffman 树

例子1
你是急救中心的接线员,当你接到一个电话时,你希望快速弄清楚患者的情况。
算法1:把所有的问题问一遍( 遍历 )
算法复杂度为$O(n)$
算法2:要尽可能减少问题,使用 二叉树
算法复杂度为$O(\log n)$
算法3: 哈夫曼算法
平衡二叉树有效的前提之一,是发生概率均匀。
然而,我们必须做到快速识别(如“病人是否有呼吸”)
哈夫曼算法是一种贪心算法
例子2
压缩领域,每个字符出现的概率是不一样的。根据概率把不同的字符赋予不同的长度,可以实现文本长度最小化。
huffman算法的Python实现
from heapq import heapify, heappush, heappop
from itertools import count
def huffman(seq, frq):
num = count()
trees = list(zip(frq, num, seq))
heapify(trees)
while len(trees) > 1:
fa, _, a = heappop(trees)
fb, _, b = heappop(trees)
n = next(num)
heappush(trees, (fa + fb, n, [a, b]))
return trees[0][-1]
###下面是调用huffman算法:
seq = 'abcdefghi'
frq = [4, 5, 6, 9, 11, 12, 15, 16, 20]
print(huffman(seq, frq))
print(huffman(seq, frq)[0][-1])
因为反复选取、合并无序表项的复杂度是平方级,所以用heapq减少了复杂度到对数级
B树
B树 非常适合用来文件索引、数据库索引,为什么呢?
如果是查找效率(即比较次数)的话,二叉树是最快的,但是,我们的文件索引是存放在磁盘上的,所以我们不仅要考虑查找效率,还要考虑磁盘的寻址加载次数哦,而这也是我们为什么要用 B 树的原因。
B 树相当于是一棵多叉查找树,对于一棵 m 阶的 B 树具有如下特性:
- 根节点至少有两个孩子。
- 每个中间节点都包含 k - 1 个元素和 k 个孩子,其中 m/2 <= k <= m。
- 每一个叶子节点都包含 k - 1 个元素,其中 m/2 <= k <= m。
- 所有的叶子节点都位于同一侧。
- 每个节点中的元素从小到大排列,节点当中的 k - 1 个元素正好是 k 个孩子包含的元素的值域划分。
B 树适合磁盘寻址的原因:内存加载是整片加载进来的,就比一个一个从磁盘读进来要快。
如果内存不足以一次把整个树加载进来,用B树很合适,每次加载一个节点。因此如果在内存中,红黑树效率更高。如果涉及磁盘操作,B树效率更高。

B+树
B+树在B树的基础上做了改造,它的数据都在叶子结点,叶子结点之间还加了指针作为链表。

B+树好用在哪呢?
在sql查询中,往往需要返回不止一条数据,而是连续多条。用B树就可能要做局部的中序遍历,而B+树因为是链表结构,所以只需要找到收尾,然后用链表取出即可。
与hash比较:
如果只返回一条数据,那hash更快,但数据库往往需要返回多条数据。B+树索引有序,有链表相连,效率就高多了。
BST 二叉搜索树
AVL树
平衡二叉树的特性:
- 是一个二叉查找树
- 每个节点的左子树和右子树的高度差至多等于1。
用途:BST(二叉查找树)的查找操作是非常快的,但有个缺点:可能“不小心”构建了一个不平衡的二叉树,最差的情况就是变成个链表。所以我们需要 平衡二叉树 (AVL)
每次插入操作,需要做“左旋”或“右旋”来保持平衡二叉树
- 左左型:右旋
- 右右型:左旋
- 左右型:先左旋,后右旋
- 右左型:先右旋,后左旋
红黑树
为什么?
平衡二叉树虽然解决了二叉树退化到链表的缺点,能够把查找时间控制在 logn,但每次插入/删除节点时,都需要左旋/右旋来平衡二叉树。
是什么?红黑树有以下特点
- 是一个二叉查找树
- 根节点是黑的
- 叶子节点都是黑的空节点
- 任何相邻节点不能同时为红蛇
- 对每个节点,其到达任意可达的叶子结点的路径上,黑色节点数目都是相同的
红黑树实际上是不太严格的平衡树,插入/删除不需要频繁调整。
trie
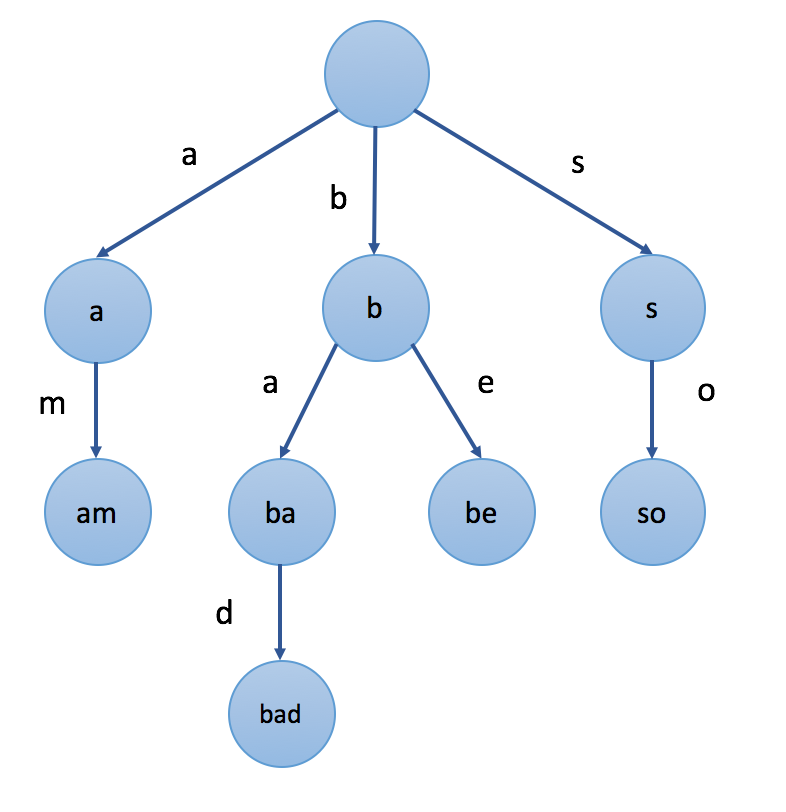
扩展阅读 trie 非常适合用来做敏感词过滤
A Trie is a special form of a Nary tree. Typically, a trie is used to store strings. Each Trie node represents a string (a prefix). Each node might have several children nodes while the paths to different children nodes represent different characters. And the strings the child nodes represent will be the origin string represented by the node itself plus the character on the path.
Here is an example of a trie:
您的支持将鼓励我继续创作!
